AI Trends Reshaping Data Engineering in 2026
Introduction
The year 2025 was an inflection point. it was the year AI shifted from chatbots to systems that perform actual work. For data engineers, this isn't just another industry shift; it's a fundamental redefinition of our role. The insights in this article are born from two sources: a deep analysis of market trends and, crucially, our hands-on experience working with pioneering customers on Alibaba Cloud's big data and AI platforms. The trends outlined below are not mere predictions; they are realities solidified in the crucible of real-world customer use cases, from global retailers to leaders in autonomous systems.
The once-clear lines between data infrastructure and AI infrastructure have blurred into a single, unified plane. Data engineering teams are no longer just managing data; they are building the foundational platforms for enterprise intelligence. This new reality demands a new perspective. The following five trends represent the most critical areas of focus for data engineers heading into 2026. This is a strategic guide to navigating the challenges and seizing the opportunities of the AI-native era.
The Merge of Data Infra and AI Infra
Trend: The Convergence of Stacks
The traditional separation between analytical data stacks (for BI and reporting) and operational AI stacks (for model training and serving) is becoming an expensive liability. In 2026, the winning strategy is convergence. We are witnessing the rise of unified platforms designed to handle the entire lifecycle of data, from ingestion and analytics to feature engineering and AI inference, within a single, cohesive environment.
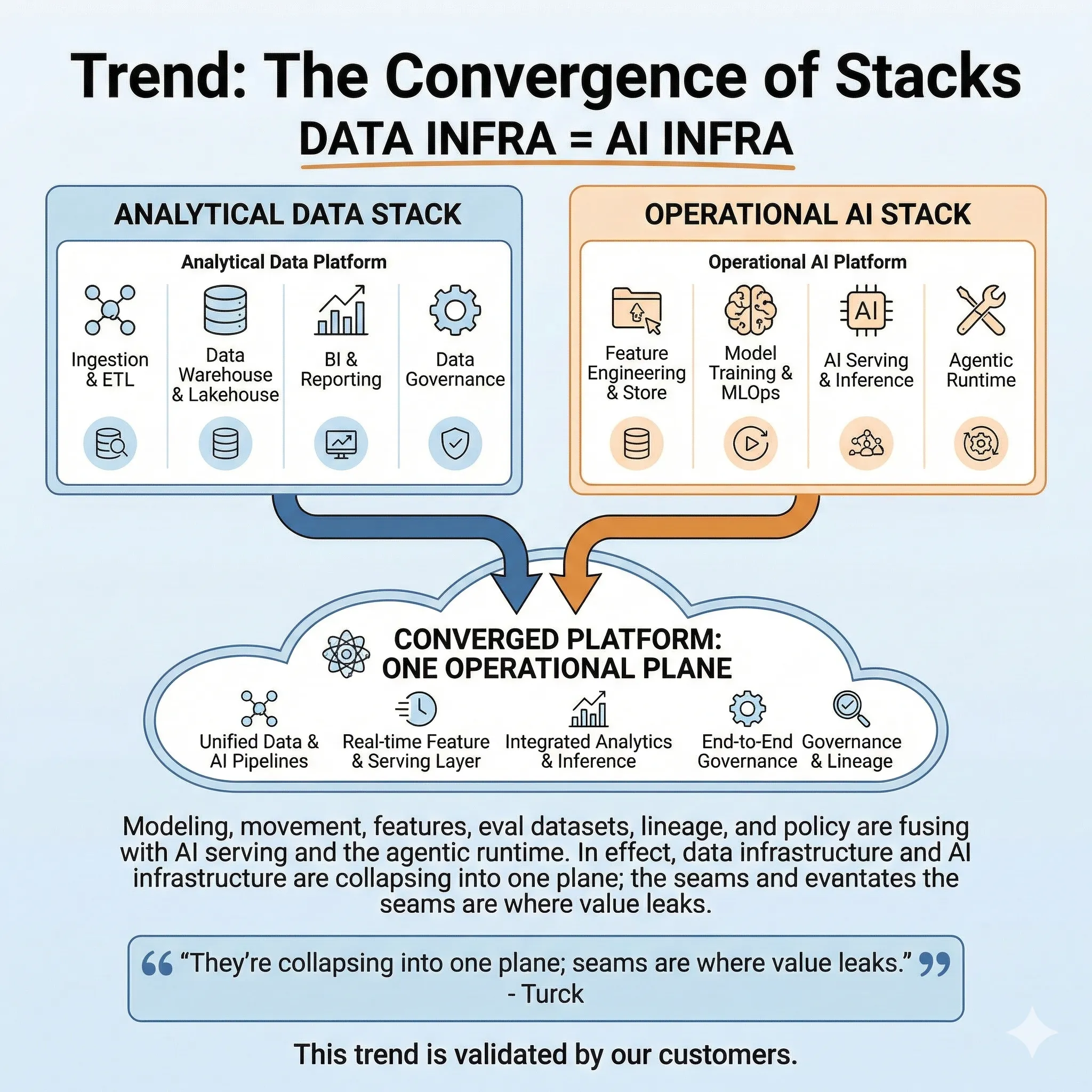
This trend is validated by our customers. Consider a major convenience store chain that needs to govern its product data. The classification of a product—its category, specifications, and unit of measure—is often subjective and inconsistent. Their solution was to build upon a unified data and AI platform. By processing structured data (product names, brand info) alongside unstructured data (product packaging images, text on packaging) within the same system, they use AI to automatically standardize product categorization, achieving a level of consistency that was previously impossible. This is the merge in action: AI and data infrastructure collapsing to solve a core business problem.
Relevance for Data Infrastructure & Engineers
This trend signals the end of siloed thinking. Your responsibility no longer ends at the data warehouse. You must now design infrastructure that serves a new primary customer: the AI agent.
Data Infra Implication: The modern data platform must be a unified engine, providing SQL analytics, vector search, and real-time processing as integrated capabilities. The goal is to eliminate the cost and latency of moving data between separate systems.
For the data engineer, this means your skillset must expand. You are no longer just a pipeline builder; you are an architect of a unified data-to-AI platform, integrating MLOps and inference patterns into the core data infrastructure.
The Real-time AI
Trend: From Data Volume to Data Freshness
The long-held belief that bigger data leads to better AI is being challenged by a new reality: data exhaustion. With research from Epoch AI suggesting that the stock of high-quality public text data could be depleted as early as 2026, the strategic focus is shifting from data quantity* to data quality* and, most importantly, *freshness* [2]. In this new paradigm, stale data is not just suboptimal; it's a liability.
This shift is a direct response to the limitations of training on static, historical datasets. As a16z astutely identified, the new bottleneck for AI is "data entropy"—the natural decay in the relevance and accuracy of data over time [3]. An AI agent making decisions based on last week's inventory or last month's customer interactions is operating at a severe disadvantage. This is why real-time capability is becoming an inherent, non-negotiable characteristic of effective AI systems.
Relevance for Data Infrastructure & Engineers
This trend forces a fundamental move away from batch-oriented architectures. For data infrastructure, this means:
Adopting Streaming-First Architectures: Change Data Capture (CDC) from operational databases, event streams from applications, and IoT sensor data must be processed as they arrive. Platforms like Kafka is no longer optional but core components.
Deploying Real-time Analytical Engines: Traditional data warehouses are ill-suited for the low-latency, high-concurrency queries demanded by AI agents. This necessitates the adoption of real-time analytical databases or unified HSAP platforms like Hologres that can serve these workloads efficiently.
For data engineers, this is a call to action to master new skills. Expertise in stream processing frameworks (like Flink or Spark Streaming) is becoming essential. You must learn to design for low latency, manage state in continuous applications, and ensure data quality and governance in a world where data never stops moving.
The Rise of Multi-Modality Data
Trend: Taming the Unstructured Universe
For decades, data engineering has primarily focused on structured data. That era is over. The vast majority of enterprise knowledge—estimated at 80%—is locked away in what a16z calls the "unstructured universe": a chaotic sludge of PDFs, images, videos, and logs [3]. In 2026, the primary challenge for data engineers is to tame this universe and transform unstructured content into structured, AI-ready assets.
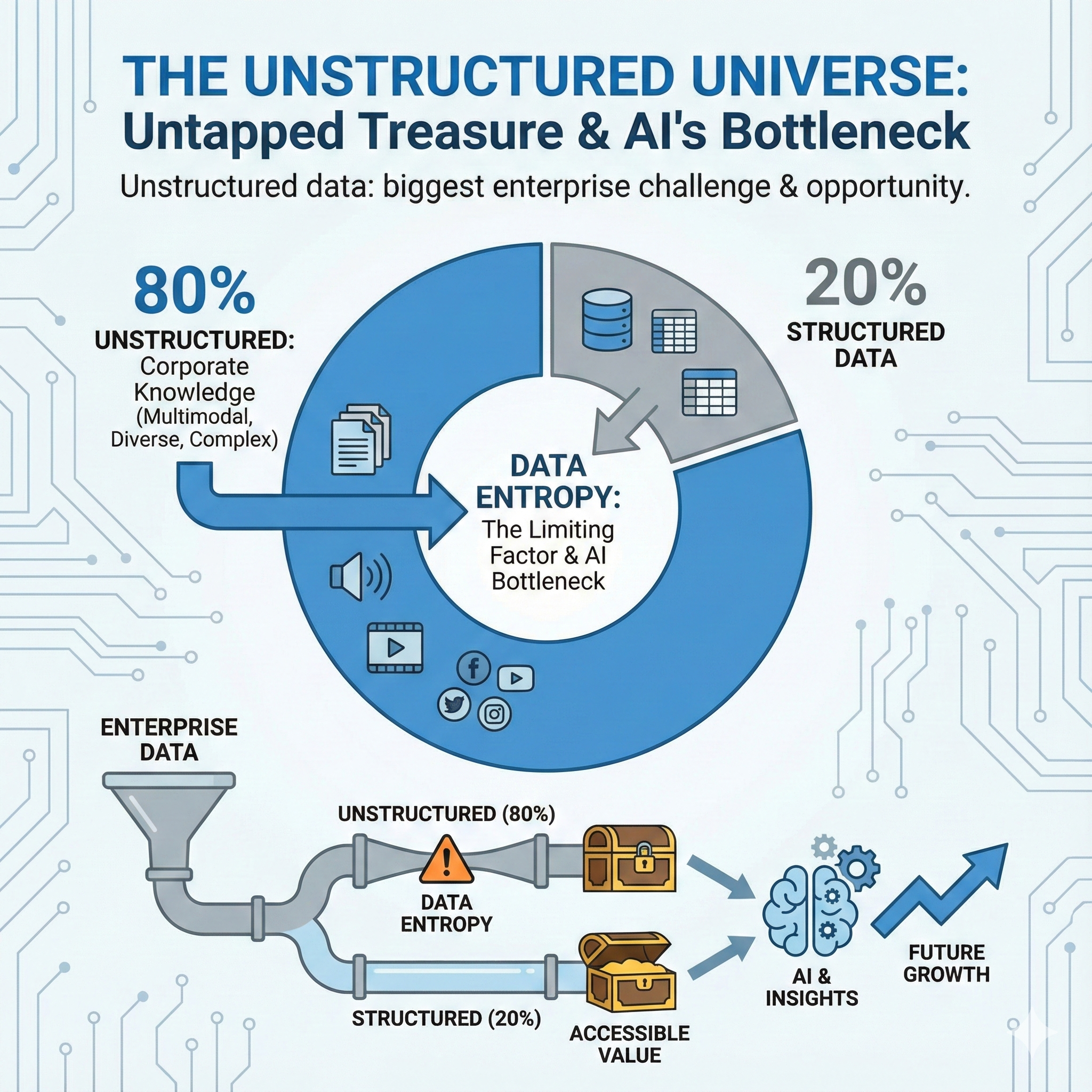
IDC predicts that unstructured data will grow at a staggering 49.3% CAGR through 2028. Our customers are living this reality. A retail client, for instance, struggled with monitoring shelf execution. They needed to ensure thousands of stores complied with preset planograms, a task that was previously unmeasurable. By leveraging a multimodal platform, they can now compare photos of store shelves against the planogram templates, using AI to automatically detect misplaced products or out-of-stock items.
In the autonomous driving sector, another customer uses Alibaba Cloud's Hologres to analyze a dataset of 100,000 driving images. By combining image data (Object Tables) with structured metadata, they perform complex queries using SQL-based AI functions for embedding, chunking, and vector search—all within the database. This unified approach allows them to improve environmental perception and vehicle recognition accuracy, a task that would have required a complex web of separate systems just a few years ago.
Relevance for Data Infrastructure & Engineers
Handling multimodal data requires a complete rethinking of the data stack.
Data Infra Implication: Your infrastructure must become a multi-format processing engine. This involves integrating object storage, vector databases, and a unified query layer like Hologres that can join and analyze structured metadata alongside unstructured content using Hybrid Search/Analytics Processing (HSAP).
For data engineers, this trend demands proficiency in embedding models, vector search, and building AI-powered extraction pipelines to create structure from chaos.
Context Engineering
Trend: The Evolution from Prompts to Knowledge
As AI models become more capable, the bottleneck for performance is shifting from how you ask (prompt engineering) to what the AI knows (context engineering). This is the most profound shift in how we interact with AI. It's about building a durable, evolving body of institutional knowledge that AI agents can draw upon to make decisions that are not just technically correct, but organizationally intelligent.
This trend is no longer a niche concept; it is now a central focus of the entire technology stack, from silicon to software. At CES 2026, NVIDIA CEO Jensen Huang declared this shift unequivocally, stating, "The bottleneck is shifting from compute to context management" . This wasn't just a talking point; it was backed by the announcement of Vera Rubin, NVIDIA's next-generation AI platform. The platform's cornerstone is a new architecture called "Context-Aware Memory," designed specifically for long-context AI agents. This move signals a fundamental truth: the industry recognizes that AI's reasoning ability is directly limited by its ability to access and process relevant context, and is investing billions to re-architect hardware accordingly. Huang’s assertion that "storage can no longer be an afterthought" confirms that context management is now a first-order problem for infrastructure design.
Relevance for Data Infrastructure & Engineers
This industry-wide pivot to context management places the data engineer at the center of the action. If AI agents are the new users, then the context they consume is the new product, and data engineers are its architects. Your role is expanding from a data provider to a context curator.
Data Infra Implication: The rise of architectures like "Context-Aware Memory" signals the need for new data systems that go beyond traditional databases. The infrastructure must support the creation of a "living data environment" that is actively queried and understood by AI. This means data catalogs are no longer just documentation—they become active systems that AI agents directly query. Semantic layers provide a shared language that both humans and AI can understand. Most importantly, comprehensive data lineage becomes the foundation of trust, allowing anyone to trace data back to its source.
For data engineers, this is a call to master the art of building these context-rich systems. It requires a deep understanding of data modeling, governance, and semantics. In the AI-native era, every great data engineer must also become a great context engineer, as you are no longer just moving data—you are building the memory of the intelligent enterprise.
Agent-Native Infrastructure
Trend: Re-architecting for Agent-Speed Workloads
The final, most forward-looking trend is the recognition that the infrastructure we have today was built for humans, and it will break under the load of autonomous agents. This leads to the need for "agent-native" infrastructure, a new architecture designed for the unique patterns of AI workloads.
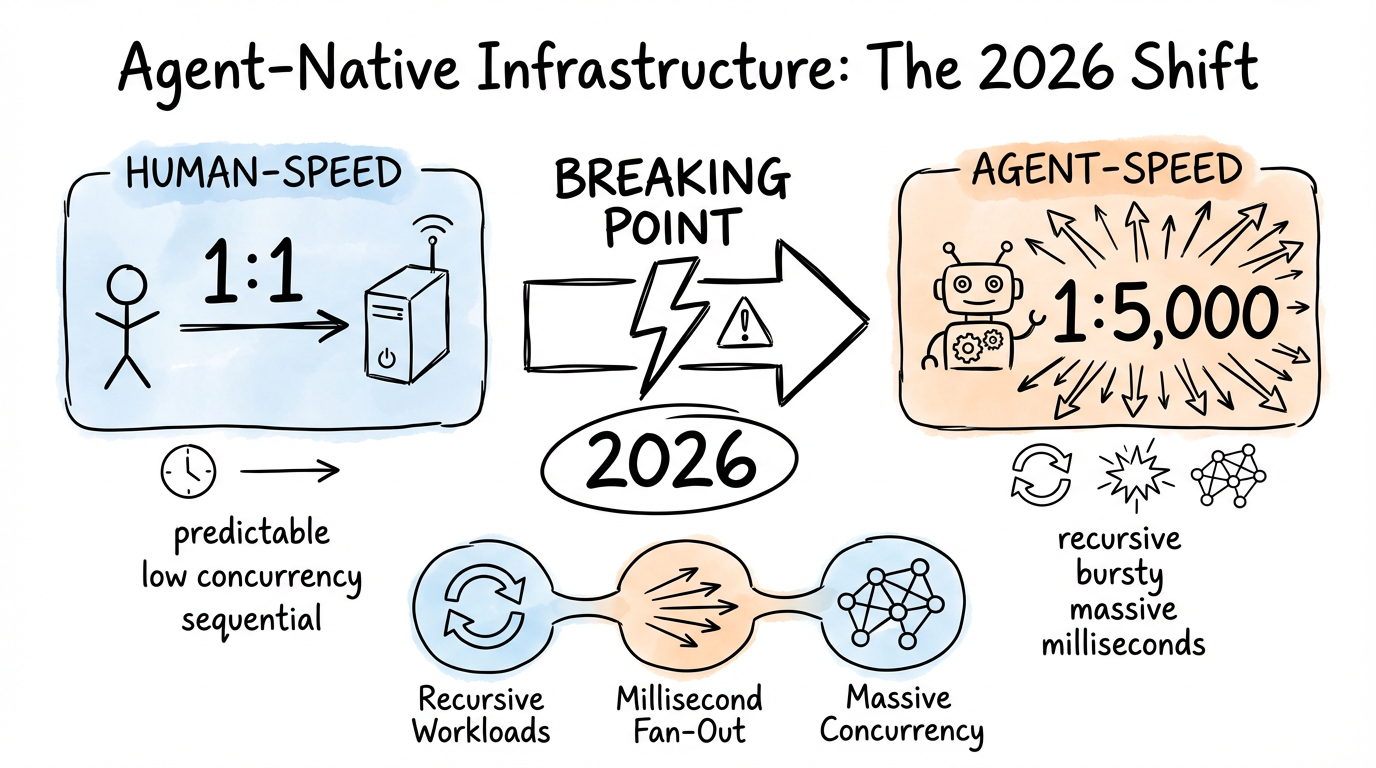
a16z's Malika Aubakirova provided the clearest articulation of this challenge, warning of an impending "infrastructure shock". She notes that our systems are not designed for a single agentic goal to recursively trigger thousands of sub-tasks, database queries, and API calls in milliseconds. This is validated by leading AI agent companies like MiniMax, who are building their advanced systems on top of scalable cloud platforms like Alibaba Cloud precisely because they require an infrastructure designed for these new, demanding workloads.
Relevance for Data Infrastructure & Engineers
This is the ultimate frontier for data engineering. It requires us to question our core architectural assumptions.
Data Infra Implication: The new architecture must treat "thundering herd" patterns as the default state. This means designing for massive parallelism and rethinking coordination. The bottleneck is no longer raw compute, but coordination: routing, locking, state management, and policy enforcement at a scale we've never seen before.
For data engineers, this is a long-term challenge that requires a deep understanding of distributed systems, asynchronous communication, and building intelligent control planes.
Building the Future with Alibaba Cloud's Unified Data and AI Platform
Navigating these trends requires a holistic platform, not a patchwork of disparate tools. Alibaba Cloud provides an integrated ecosystem that empowers data engineering teams to build for the AI-native era by focusing on innovation instead of complex integration.
At the heart of this ecosystem is DataWorks, which serves as the central hub for unified data development and governance. It provides a single pane of glass to orchestrate the entire data lifecycle. From this control center, data engineers can manage the full spectrum of data processing. For massive-scale historical analysis, MaxCompute delivers robust and cost-effective batch processing capabilities. For data in motion, Realtime Compute for Apache Flink offers a world-class stream processing engine to handle data as it arrives.
The true power of convergence is realized when these data streams are unified for analysis and serving. This is the role of Hologres, a next-generation data warehouse built on a Hybrid Search/Analytics Processing (HSAP) architecture. It seamlessly serves both real-time and batch data and is purpose-built for the AI era with native vector search and multimodal data capabilities, eliminating the need for separate, specialized systems.
Ultimately, this entire, well-governed data ecosystem exists to power intelligent applications. The Platform for AI (PAI) provides an one-stop AI development platform for developers and enterprises. It delivers end-to-end capabilities across dataset management, compute orchestration, model development and training, deployment and serving, plus AI asset and security governance. With 400+ built-in foundation models and 200+ best-practice templates, PAI enables high-performance, highly reliable AI engineering.
By providing one platform that addresses all five trends, Alibaba Cloud empowers data engineering teams to move beyond the challenges of integration and focus on what truly matters: building the intelligent enterprise of the future.